Apache Hadoop is an open-source software framework written in Java for distributed storage and distributed process, and it handles the very large size of data sets by distributing it across computer clusters.
Rather than rely on hardware high availability, Hadoop modules are designed to detect and handle the failure at the application layer, so gives you high-available service.
Hadoop framework consists of following modules,
- Hadoop Common – It contains a common set of libraries and utilities that support other Hadoop modules
- Hadoop Distributed File System (HDFS) – is a Java-based distributed file-system that stores data, providing very high-throughput to the application.
- Hadoop YARN – It manages resources on compute clusters and using them for scheduling user’s applications.
- Hadoop MapReduce – is a framework for large-scale data processing.
This guide will help you to install Apache Hadoop on CentOS 7, Ubuntu 18.04 & Debian 9. This guide should also work on Ubuntu 16.04.
Prerequisites
Switch to the root user.
su -
OR
sudo su -
Install Java
Apache Hadoop requires Java version 8 only. So, you can choose to install either OpenJDK or Oracle JDK.
READ: How To Install Oracle Java on CentOS 7 / RHEL 7
READ: How To Install Oracle Java on Ubuntu 18.04
READ: How To Install Oracle Java on Debian 9
Here, for this demo, I will be installing OpenJDK 8.
### CentOS 7 / RHEL 7 ### # yum -y install java-1.8.0-openjdk wget ### Ubuntu 18.04 / 16.04 & Debian 9 ### # apt update # apt install -y openjdk-8-jdk wget
Check the Java version.
# java -version
Output:
openjdk version "1.8.0_212" OpenJDK Runtime Environment (build 1.8.0_212-b04) OpenJDK 64-Bit Server VM (build 25.212-b04, mixed mode)
Create Hadoop user & Enable Passwordless Authentication
It is recommended to create a regular user to configure and run Apache Hadoop. So, create a user named hadoop and set a password.
# useradd -m -d /home/hadoop -s /bin/bash hadoop # passwd hadoop
Once you created a user, configure passwordless ssh to the local system. Create an ssh key using the following commands.
# su - hadoop $ ssh-keygen $ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys $ chmod 600 ~/.ssh/authorized_keys
Verify the passwordless communication to the local system. If you are doing ssh for the first time, type yes to add RSA keys to known hosts.
$ ssh 127.0.0.1
Install Apache Hadoop
Download Hadoop
You can visit Apache Hadoop page to download the latest Hadoop package, or you can issue the following command in terminal to download Hadoop v3.2.0.
$ wget https://www-us.apache.org/dist/hadoop/common/stable/hadoop-3.2.0.tar.gz $ tar -zxvf hadoop-3.2.0.tar.gz $ mv hadoop-3.2.0 hadoop
Install Hadoop
Hadoop supports three modes of clusters
- Local (Standalone) Mode – It runs as a single java process.
- Pseudo-Distributed Mode – Each Hadoop daemon runs in a separate process.
- Fully Distributed Mode – It is an actual multinode cluster ranging from few nodes to extremely large cluster.
Setup environmental variables
Here, we will be configuring Hadoop in Pseudo-Distributed mode. To start with, set environmental variables in the ~/.bashrc file.
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.212.b04-0.el7_6.x86_64/jre ## Change it according to your system export HADOOP_HOME=/home/hadoop/hadoop ## Change it according to your system export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export HADOOP_YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
Apply environmental variables to the current session.
$ source ~/.bashrc
Modify Configuration files
Edit the Hadoop environmental file.
vi $HADOOP_HOME/etc/hadoop/hadoop-env.sh
Set JAVA_HOME environment variable.
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.212.b04-0.el7_6.x86_64/jre
Hadoop has many configuration files, and we need to edit them depends on the cluster modes we set up (Pseudo-Distributed).
$ cd $HADOOP_HOME/etc/hadoop
Edit core-site.xml.
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://server.itzgeek.local:9000</value>
</property>
</configuration>
Edit hdfs-site.xml.
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopdata/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopdata/hdfs/datanode</value>
</property>
</configuration>
Create NameNode and DataNode directories in hadoop user’s home directory.
mkdir -p ~/hadoopdata/hdfs/{namenode,datanode}
Edit mapred-site.xml.
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
Edit yarn-site.xml.
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
Now format the NameNode using the following command. Do not forget to check the storage directory.
$ hdfs namenode -format
Output:
. . . . . . 2019-05-12 06:38:42,066 INFO common.Storage: Storage directory /home/hadoop/hadoopdata/hdfs/namenode has been successfully formatted. 2019-05-12 06:38:42,169 INFO namenode.FSImageFormatProtobuf: Saving image file /home/hadoop/hadoopdata/hdfs/namenode/current/fsimage.ckpt_0000000000000000000 using no compression 2019-05-12 06:38:42,483 INFO namenode.FSImageFormatProtobuf: Image file /home/hadoop/hadoopdata/hdfs/namenode/current/fsimage.ckpt_0000000000000000000 of size 401 bytes saved in 0 seconds . 2019-05-12 06:38:42,501 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 2019-05-12 06:38:42,516 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at server.itzgeek.local/192.168.1.10 ************************************************************/
Firewall
Allow Apache Hadoop through the firewall. Run the below commands as the root user.
FirewallD:
firewall-cmd --permanent --add-port=9870/tcp firewall-cmd --permanent --add-port=8088/tcp firewall-cmd --reload
UFW:
ufw allow 9870/tcp ufw allow 8088/tcp ufw reload
Start the NameNode daemon and DataNode daemon by using the scripts in the /sbin directory, provided by Hadoop.
$ start-dfs.sh
Output:
Starting namenodes on [server.itzgeek.local] server.itzgeek.local: Warning: Permanently added 'server.itzgeek.local,192.168.1.10' (ECDSA) to the list of known hosts. Starting datanodes localhost: Warning: Permanently added 'localhost' (ECDSA) to the list of known hosts. Starting secondary namenodes [server.itzgeek.local] 2019-05-12 06:39:14,171 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Open your web browser and go to the below URL to browse the NameNode.
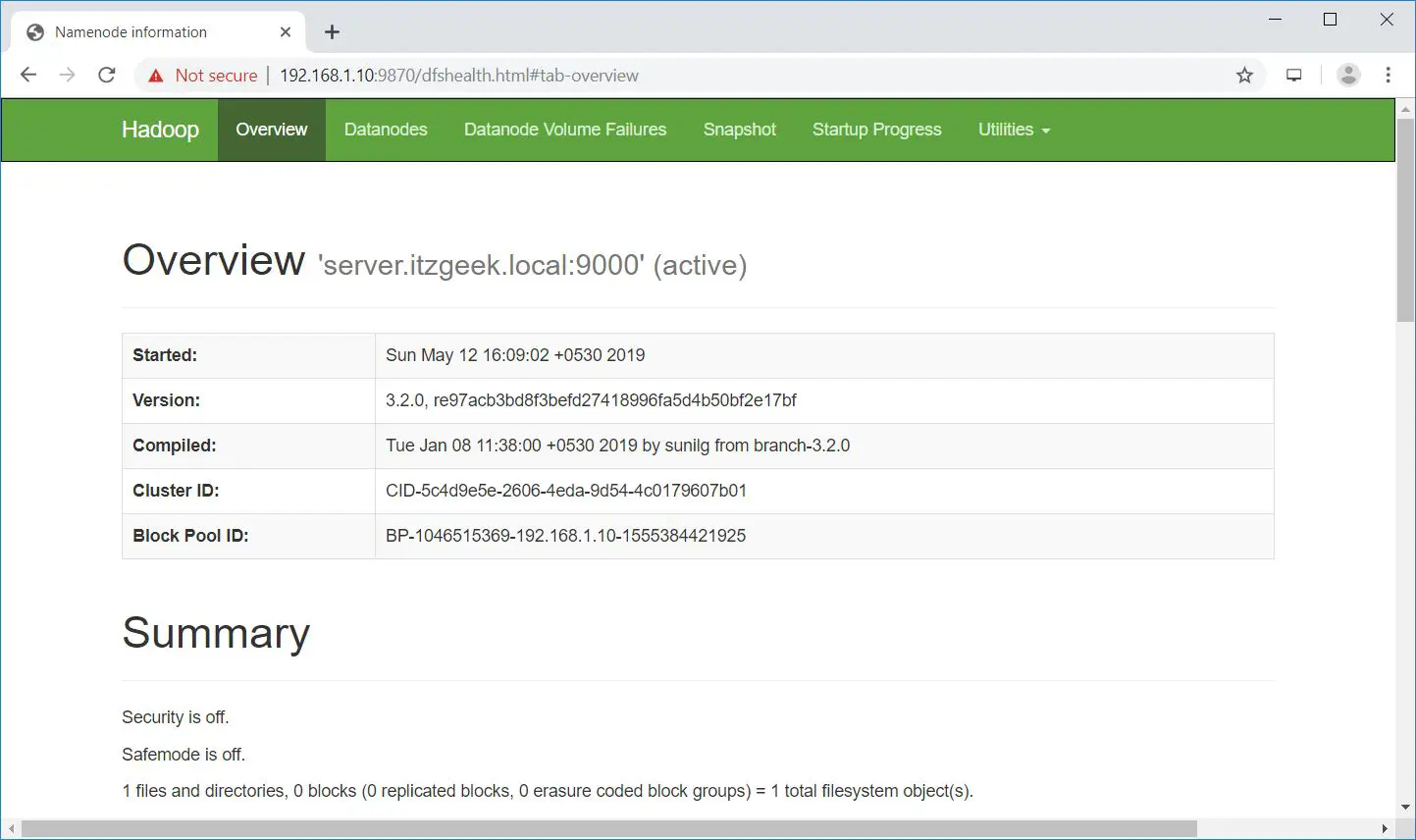
Start ResourceManager daemon and NodeManager daemon.
$ start-yarn.sh
Output:
Starting resourcemanager Starting nodemanagers
Open your web browser and go to the below URL to access the ResourceManager.
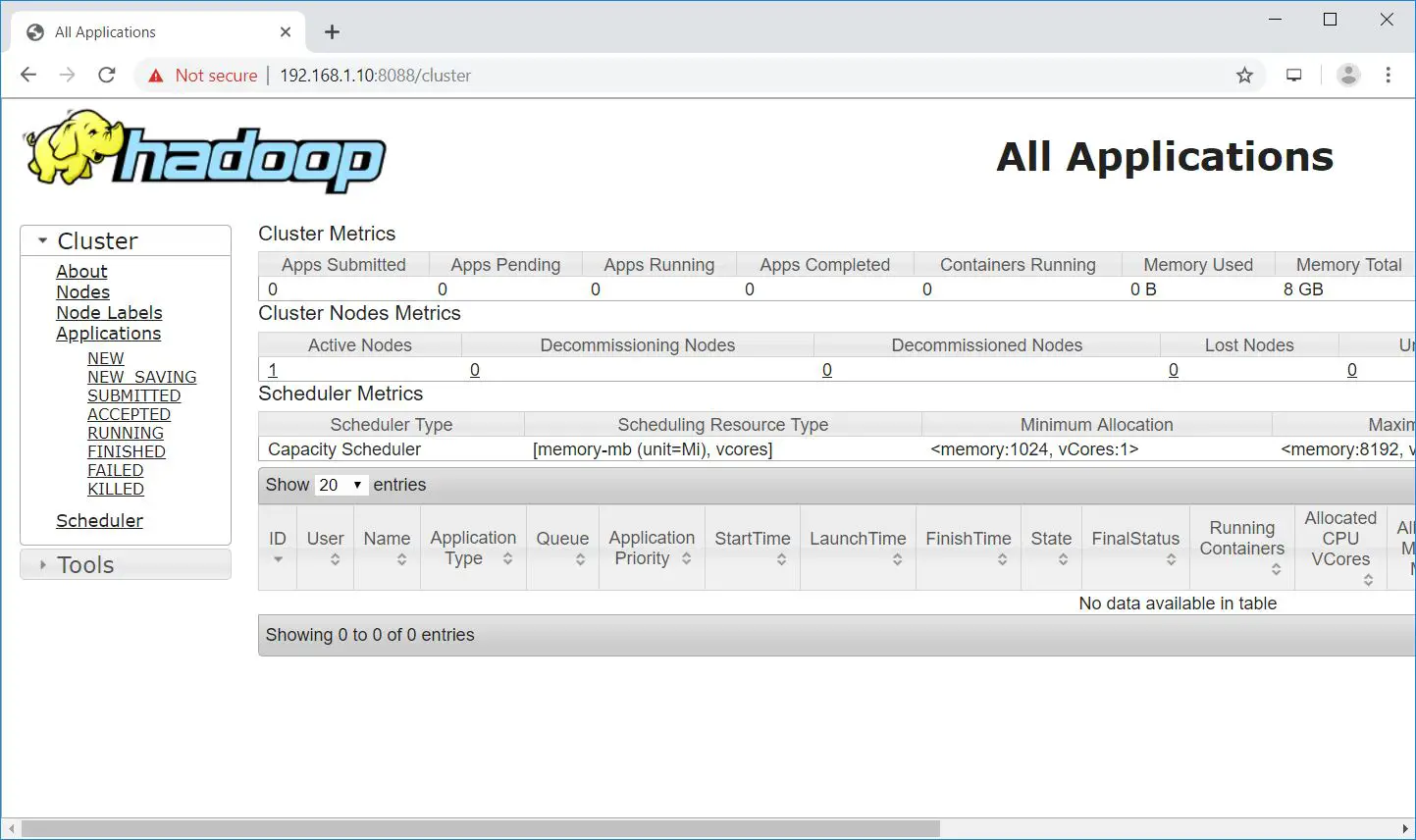
Test Hadoop Single Node Cluster
Before carrying out the upload, let us create a directory at HDFS.
$ hdfs dfs -mkdir /raj
Let us upload a file into HDFS directory called raj.
$ hdfs dfs -put ~/.bashrc /raj
Uploaded files can be viewed by going to NameNode >> Utilities >> Browse the file system in NameNode.
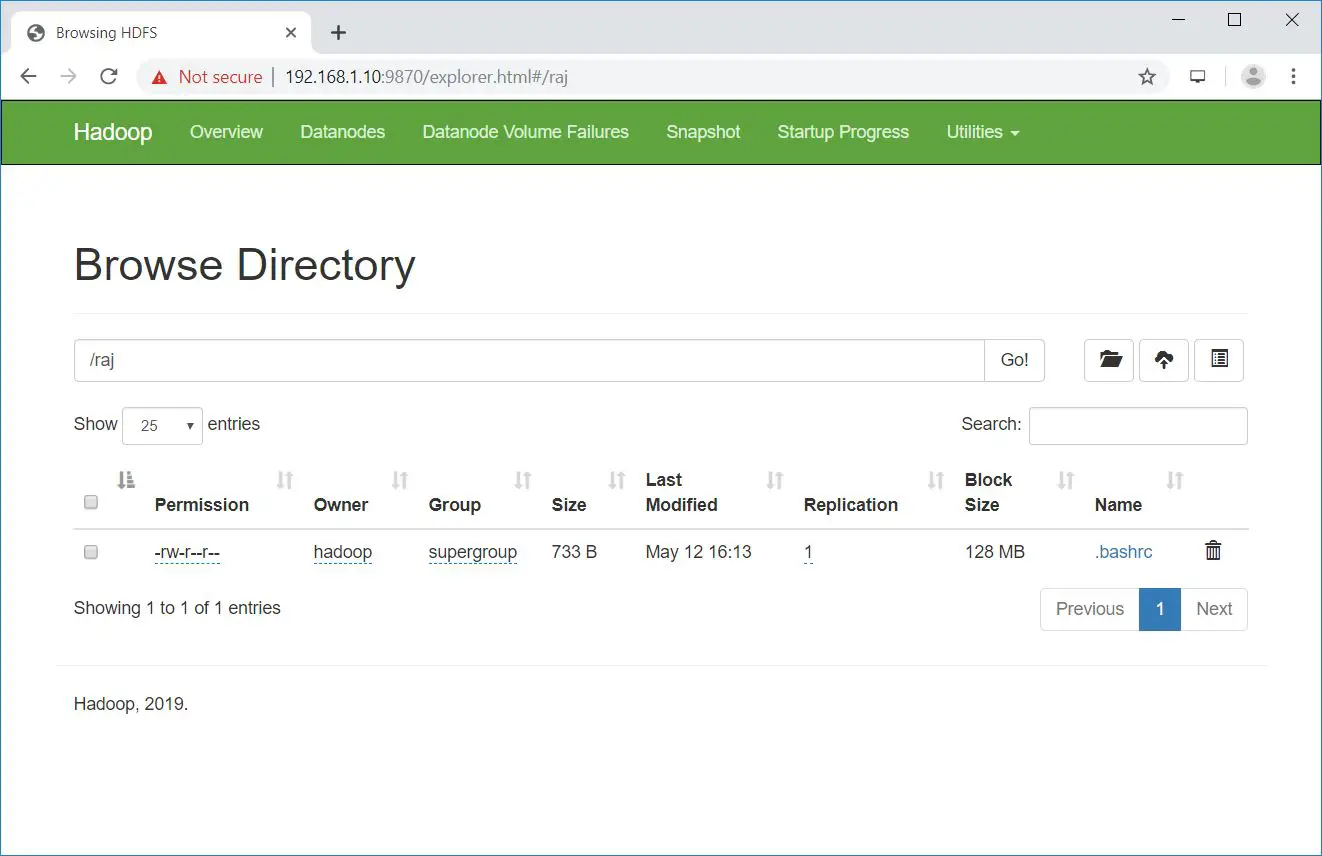
Copy the files from HDFS to your local file systems.
$ hdfs dfs -get /raj /tmp/
You can delete the files and directories using the following commands.
hdfs dfs -rm -f /raj/.bashrc hdfs dfs -rmdir /raj
Conclusion
That’s All. You have successfully configured a single node Hadoop cluster and tested the hadoop filesystem. Please share your feedback in the comments section.